Pros and Cons of Cloud Data Warehouse | Cloud Data Warehouse Architecture
Pros and Cons of Cloud Data Warehouse | Cloud Data Warehouse Architecture

Companies today are dealing with data of varying sizes and frequencies. These organizations are looking beyond the constraints of traditional data architectures to enable cloud scale analytics, data science, and machine learning on all this data. The lakehouse architecture pattern is one architecture pattern that addresses many of the challenges of traditional architectures.
Lakehouses combine data lakes' low cost and flexibility with data warehouses' dependability and performance. Several features are provided by the lakehouse architecture.
In this blog, we explain the technical architecture of the data lakehouse and illustrate the benefits of the same.
Pros of Cloud Data warehouse
The most compelling reason for adopting a data lake architecture is to separate the storage and compute layers. But what's the big deal about decoupling storage and compute? This becomes clear when we consider that compute is nearly ten times more expensive than storage. Computations in a data lake during batch processing are only performed for a few hours each day. Big data clusters are created just before the job begins and destroyed as soon as the job is completed.
Easy Cloud Data Warehouse Architecture
Let us understand the Architecture a bit.
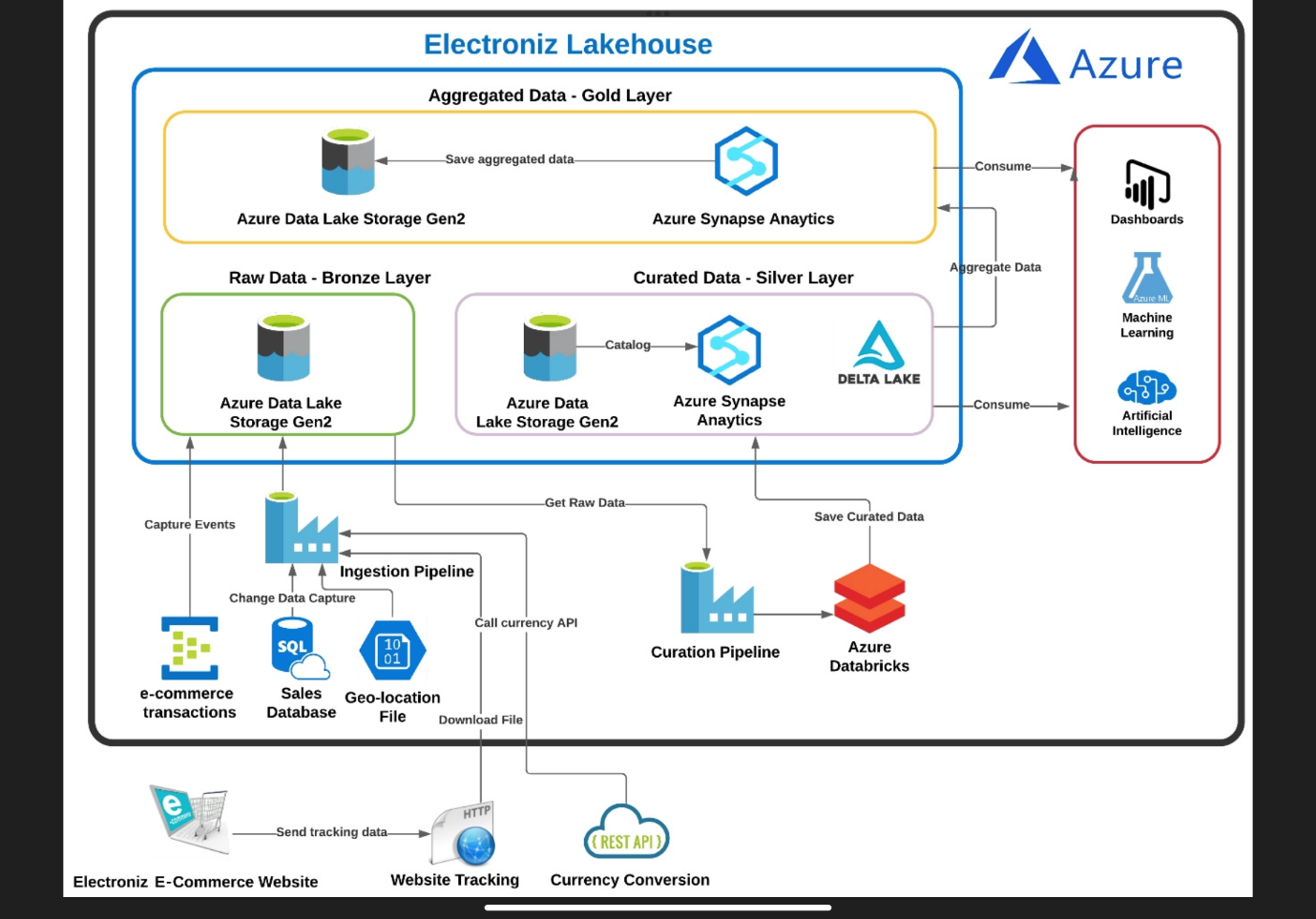
The Architecture of a Data Lake storage is depicted below;
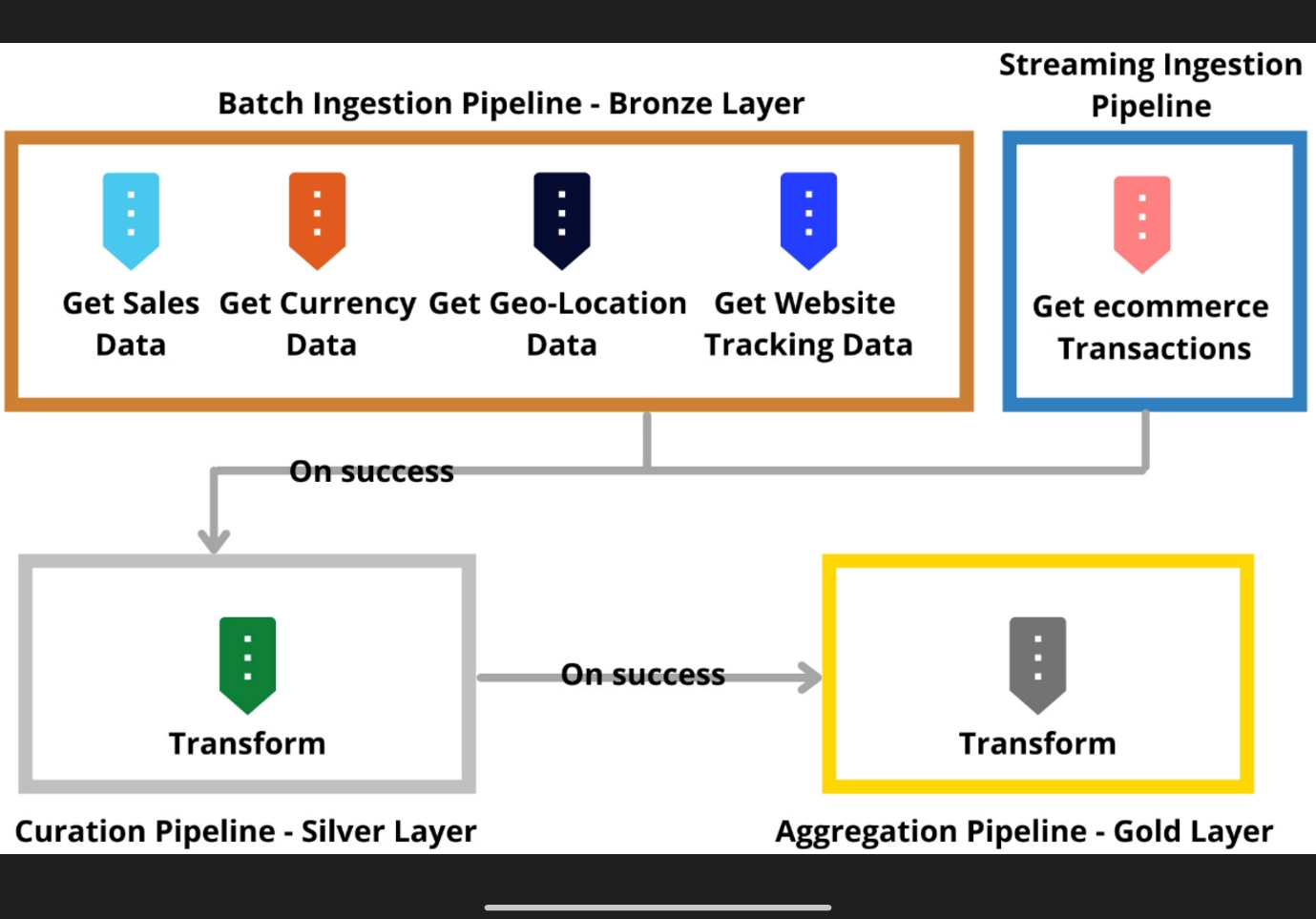
RAW Data --- Bronze Layer:
Batch data ingested from Azure Data Factory (ADF) and Event Data such as IOT data are stored in Azure Data Lake as RAW data in the same shape and form as data ingested from source systems.
CURATED DATA --- Silver layer:
Azure Databricks is used to curate RAW data. Using Delta Lake, this layer will merge incremental data from data sources. Curated tables will be visible to Azure synapse users and used for data analytics, machine learning, and other purposes.
AGGREGATED DATA --- GOLD Layer:
Aggregated results are stored in Azure Data Lake store.
- Insights from both structured and unstructured data.
- It caters to different organizational personas.
- It makes it easier to implement a strong governance framework.
- It addresses data warehouse challenges such as architectural complexity, balancing flexibility and discipline.
- Enables domain-driven Microservices-based Data Mesh Architecture with the ability to share data while ensuring domain isolation.
The image illustrates the above layer and reference Architecture of Azure Data Lake storage
The Data Mesh Architecture, the greatest Architectural benefit of Data Lake Storage design is as below:
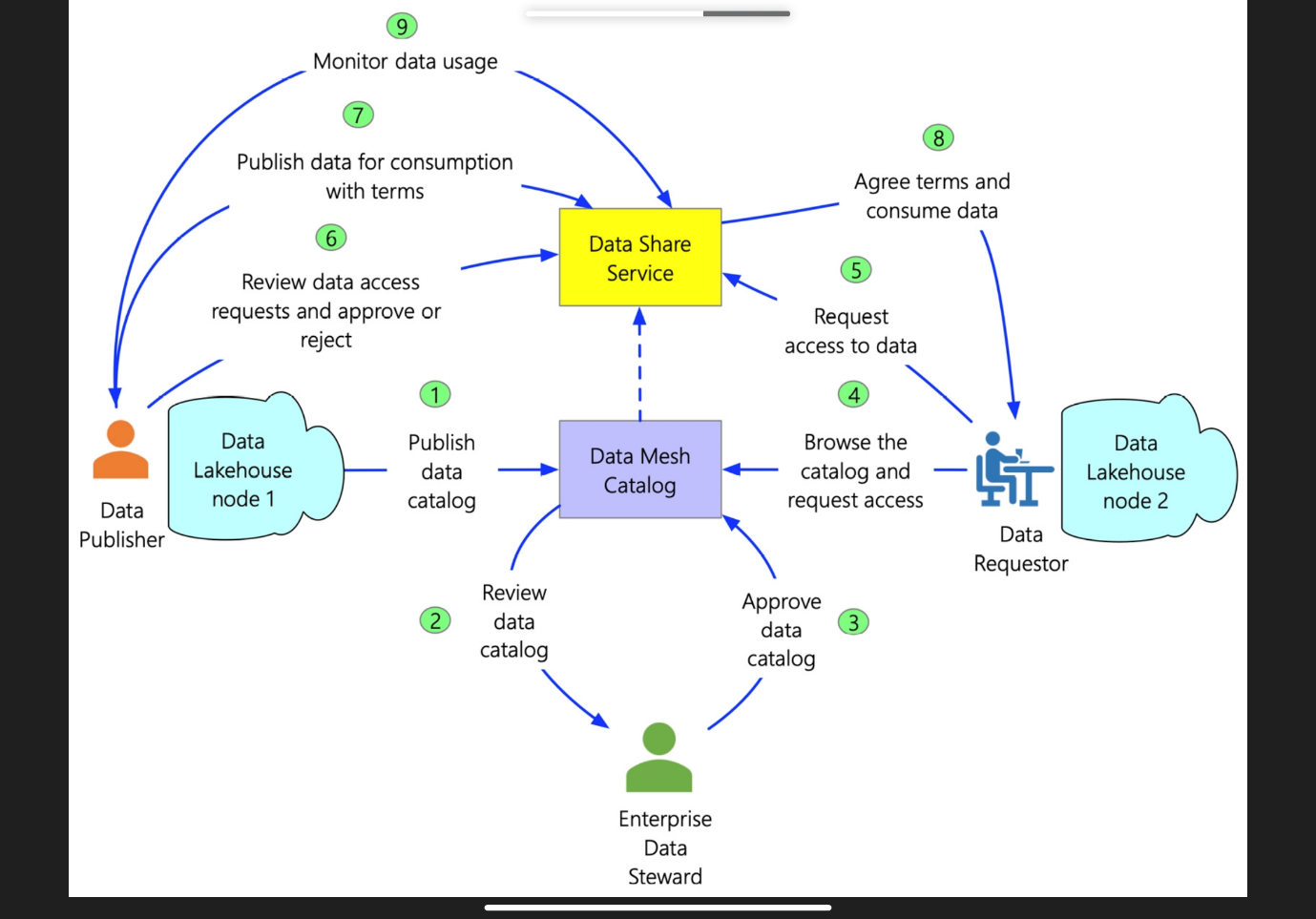
Each domain data lake house can have its own data catalogue, and the master catalogue is the data mesh catalogue.
Cons of Cloud data warehouse
Cloud data warehouses and data lake storage face the following challenges:
Handling Data Validation
Data Lake pipelines will handle data validation and schema adoption. The schema of incoming files changes by the time things are moved to production.
Concerns about data security and data governance
Regulations such as GDPR impose legal accountability and impose severe penalties for noncompliance. As a result, proper security and effective methods for data discovery, classification, and lineage tracking must be established. Data cataloguing, tagging, and the establishment of access rules are all required.
Conclusion
To summarize, we discussed Data Lake house in all of its facets in this blog. The data lake house is the most recent and hotly debated technology topic in enterprise data. Many enterprise solutions have been simplified as a result of a thorough understanding of this concept, and the true business value of data has been determined. We have also summarized a few limitations of this concept, which are most likely to be overcome in a few months.
Worried about getting the right digital infrastructure? We are here to help you with any technical, management, governance, assessment, migration, modernization, or optimization questions you may have.
Please contact our experts at Azurehelpdesk@sonata-software.com. Our team will be delighted to share their solutions and ideas with you at no cost.